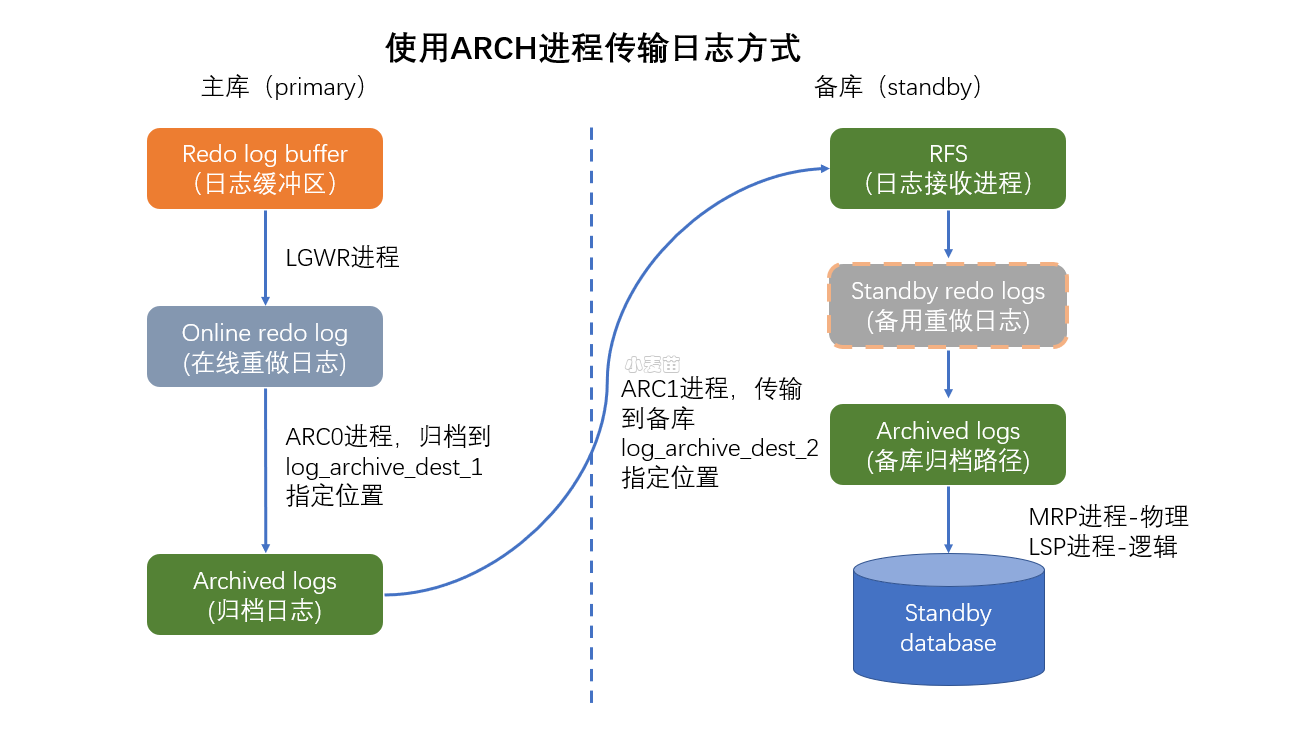
原 密码保护GreenPlum之搭建gpdr灾备环境(容灾环境、数据实时同步)
Tags: 原创GreenPlum高可用实时同步灾备gpdr两地三中心容灾异地容灾
👉 本文共约10044个字,系统预计阅读时间或需38分钟。
相关文章
- 密码保护GreenPlum中的灾备(数据实时同步)
- 密码保护Greenplum中检测和恢复故障的master实例(gpinitstandby命令)
- 密码保护启动或关闭GP库时报错 could not create socket: Address family not supported by protocol
- 密码保护含有gp_dist_random的函数在 Greenplum 中计算结果错误问题
- 密码保护canceling statement due to user request的几种情况
- 密码保护GreenPlum启用gp_wlm、gpcc_wlm的schema、工作负载管理规则功能
- 密码保护GreenPlum + pgpool 架构缓存查询结果,加速web界面展示,并配置脚本开发自动故障转移高可用功能
- 密码保护GreenPlum重装一个数据节点后的恢复
- 密码保护迁移GreenPlum中gpperfmon库
- 密码保护GreenPlum中IN条件有1000多,生成执行计划需要30s的解决办法
- 密码保护GreenPlum中的PXF(Platform Extension Framework)介绍
- 密码保护当GP源库和目标库的segment数不一样时的备份和恢复注意事项
- 密码保护GreenPlum 7中如何查询所有的分区表
- 密码保护GreenPlum 6中启用资源组后,报错 ERROR: insufficient memory reserved for statement (execHHashagg.c:1400)
- 密码保护GreenPlum 7中的资源组
- 密码保护pgbouncer启动报错evdns_base_new failed Segmentation fault (core dumped)
- 密码保护GreenPlum启用资源组后,gpcc不能展示界面,报错 Error: pq: column "memory_quota" does not exist
- 密码保护GreenPlum启用资源组后,gpcc不能启动,GP也查询报错
- 密码保护gpcc启动报错Failed to detect agent status within 120 seconds.
- 密码保护gpcc自动关闭的情况